The last year has definitely been the year of the large language models (LLMs), with ChatGPT becoming a conversation piece even among the least technologically advanced.
Hire the best developers in Latin America. Get a free quote today!
Contact Us Today!GPT-4 and GPT-3.5-Turbo, the latest models from the Microsoft-backed AI company OpenAI, are cutting edge technologies but as of now, they come with a few limitations. One such limitation is that the large language model that these GPT models are based on, only has knowledge up to a certain date. That’s where Langchain comes in. Langchain provides tools to enhance their capabilities. And one of those capabilities is allowing these GPTs to connect with the world’s most popular search engine, Google Search. This integration can revolutionize the way we interact with AI-generated content, allowing users to leverage real-time, up-to-date information and generate more accurate and relevant responses.
Scaling AI agents requires specialized talent. If you need engineers to implement this, check out our nearshore staff augmentation services for pre-vetted AI developers.
In this guide, you will learn how to use LangChain Tools to build your own custom GPT model with browsing capabilities. Here, browsing capabilities refers to allowing the model to consult external sources to extend its knowledge base and fulfill user requests more effectively than relying solely on the model’s pre-existing knowledge.
This post is a fantastic starting point for anyone who wants to dive into the world of prompt engineering with LangChain.
By the end of this post you will:
- Get hands-on experience with LangChain and its features
- Understand the underlying concepts of prompt engineering
- Explore the potential of language models like OpenAI’s GPT family
- Integrate third-party APIs, in this case Google Search, into a chatbot
Let’s get started!
What is Langchain?
Red hot AI startup LangChain provides a very popular and useful open source framework that helps you build impactful products and services using Large Language Models in as little as two dozen lines of code.
A Large Language Model is an AI algorithm that has been trained on a massive amount of text data applying deep learning techniques with lots of parameters that provide explicit instructions or some examples of how to successfully complete a task. Training the foundational models for LLM is hard and requires time, money, and resources. But thankfully, due to some large corporations, we have some pre-trained models to use like GPT-3 and GPT-4 from OpenAI, LLaMA by Meta, and PaLM2 by Google.
Langchain provides you with a lot of high level functions which helps you utilize your favorite LLM to build chat models and LLM-based systems that have access to external data sources like PDF files, Private Data Sources, and the Public Internet.
With the help of this open-source framework, developers can create dynamic, data-responsive apps that use the most recent advances in natural language processing.
LangChain offers a wide variety of use cases, such as:
- Text Generation
- Text Summarization
- Text to Image Generation
- Q&A over a Knowledge Base
- Content Tagging
- Conversational AI
- Data Analysis
- Data Extraction
- Code Completion
- Interacting with APIs
So let’s explore how we can make use of LangChain to connect OpenAIs LLMs with Google Search.
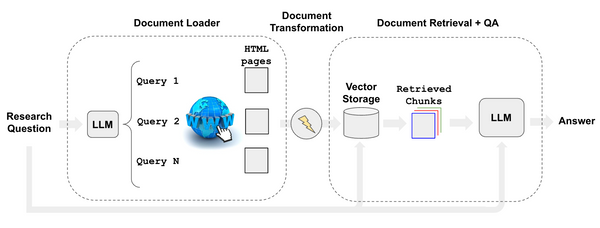
How Does the LangChain Google Search Bot Work?
Our LangChain Google Search Bot should do approximately what a human does; search a topic, choose selected links, skim the link for useful pieces of information, and return to the search in an iterative exploration.
Therefore in our implementation; given a user question, the LangChain Google Search Bot should:
- Use an LLM to generate multiple relevant search queries from a single LLM prompt, ensuring a wide range of query terms that are key to obtaining comprehensive results.
- Execute a search for each query but in parallel. This simultaneous execution of multiple search queries accelerates the data collection process, saving precious time. Performing multiple searches simultaneously and, in turn, “reading” multiple pages simultaneously is a unique advantage that AIs can uniquely exploit.
- As the queries return results, the system’s algorithms will identify the top K links for each query and the bot will scrape the full content of the pages in parallel. This prioritization ensures that the most promising and relevant sources of information are given precedence.
- The accumulated data from the web pages is then meticulously indexed into a dedicated vector store (Chroma DB). This indexing process is crucial for efficient retrieval and comparison of information in subsequent steps.
- Lastly, the LangChain Google Search Bot matches the original search queries generated by the LLM with the most relevant documents stored in the vectorstore. This ensures that users are presented with accurate and contextually appropriate results.
Collectively, these steps fall into the following architecture:
Implementation
Step 1: Environment Setup
1: Install Python Packages
First we’ll need to install the required packages first:
pip install langchain openai chromadb
This pip install command installs the following python packages:
- The Langchain library
- The library of our LLM provider (Today I’ll be using the OpenAI GPT library but you can also use other LLM services supported by LangChain)
- chromadb, an in-memory vector database
2: Get your OpenAI API Key
To use the OpenAI library, you’ll need to first get OpenAI API Key.
Here’s how you can get your OpenAI API key:
- Visit https://openai.com/ and create an account.
- After you logged in, select the API menu to get to your account dashboard.

- Go to https://platform.openai.com/account/api-keys or simply select View API Keys in the side pop up menu. You might need to set up billing info before you can create a key.
- If you have a key already, then you can use your existing key. If you don’t have any, proceed to select Create new secret key.
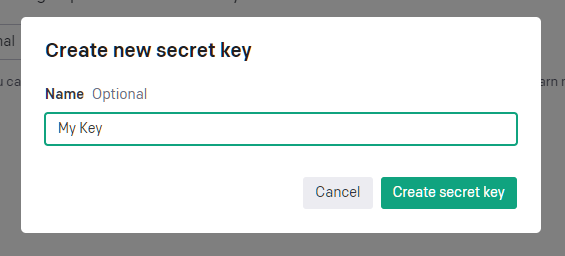
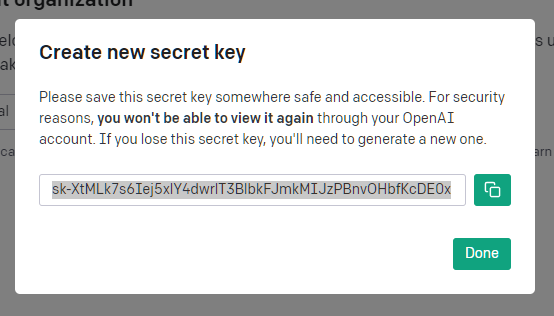
- Now copy your code and save it well as you can’t go back and copy it again after you select Done.
3: Set up a Custom Search Engine
You need to set up a custom search engine so that you can search the entire web. To do so:
Create a GOOGLE_API_KEY in the Google Cloud credential console (https://console.cloud.google.com/apis/credentials).
Next create a GOOGLE_CSE_ID using the Programmable Search Engine (https://programmablesearchengine.google.com/controlpanel/create).
The GoogleSearchAPIWrapper library from the Python package LangChain will use these two values.
If you have reached this point, you have completed the basic setup for your LangChain project journey. Good job!
4: Set the Environment Variables
Get the OpenAI API Key, Google API Key and the Google Custom Search Engine (CSE) ID you obtained from the previous step, and set them as environment variables.
import os
# Load Environment Variables
os.environ["OPENAI_API_KEY"] = "[INSERT YOUR OPENAI API KEY HERE]"
os.environ["GOOGLE_CSE_ID"] = "[INSERT YOUR GOOGLE CSE ID HERE]"
os.environ["GOOGLE_API_KEY"] = "[INSERT YOUR GOOGLE API KEY HERE]"
Step 2: Setup a Vectorstore
A common method for handling unstructured data involves embedding it into vectors and storing these embeddings. When querying, the system embeds the query and retrieves the most similar vectors from the stored data. This approach simplifies data management, and a vector store handles the storage and retrieval of these embedded data.
We use chromadb, an in-memory vector database.
import os
from langchain import OpenAI
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
# Load Environment Variables
os.environ["OPENAI_API_KEY"] = "[INSERT YOUR OPENAI API KEY HERE]"
os.environ["GOOGLE_CSE_ID"] = "[INSERT YOUR GOOGLE CSE ID HERE]"
os.environ["GOOGLE_API_KEY"] = "[INSERT YOUR GOOGLE API KEY HERE]"
# Vectorstore
vectorstore = Chroma(embedding_function=OpenAIEmbeddings(), persist_directory=”./chroma_db_oai”)
Step 3: Initiate GTP
To initiate the language model, we use OpenAI’s GPT-3.5 Turbo, designed for natural language processing. We set the model name to “gpt-3.5-turbo-16k” with a 16,000 token limit. The temperature parameter is set to 0 for deterministic responses, with streaming enabled for real-time processing.
import os
from langchain.chat_models.openai import ChatOpenAI
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
# Load Environment Variables
os.environ["OPENAI_API_KEY"] = "[INSERT YOUR OPENAI API KEY HERE]"
os.environ["GOOGLE_CSE_ID"] = "[INSERT YOUR GOOGLE CSE ID HERE]"
os.environ["GOOGLE_API_KEY"] = "[INSERT YOUR GOOGLE API KEY HERE]"
# LLM
llm = ChatOpenAI(model_name=”gpt-3.5-turbo-16k”, temperature=0, streaming=True,openai_api_key=”your_api_key”)
# Vectorstore
vectorstore = Chroma(embedding_function=OpenAIEmbeddings(), persist_directory=”./chroma_db_oai”)
Step 4: Initiate Memory Retriever
One crucial aspect of effective conversation is the ability to reference information introduced earlier in the discussion. A LLM application should be able to access a certain window of past messages directly.
LangChain provides a lot of utilities to handle the memory for LLMs based on different use cases.
import os
from langchain.chat_models.openai import ChatOpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.memory import ConversationSummaryBufferMemory
# Load Environment Variables
os.environ["OPENAI_API_KEY"] = "[INSERT YOUR OPENAI API KEY HERE]"
os.environ["GOOGLE_CSE_ID"] = "[INSERT YOUR GOOGLE CSE ID HERE]"
os.environ["GOOGLE_API_KEY"] = "[INSERT YOUR GOOGLE API KEY HERE]"
# LLM
llm = ChatOpenAI(model_name=”gpt-3.5-turbo-16k”, temperature=0, streaming=True,openai_api_key=”your_api_key”)
# Vectorstore
vectorstore = Chroma(embedding_function=OpenAIEmbeddings(), persist_directory=”./chroma_db_oai”)
# Memory for Retriever
memory = ConversationSummaryBufferMemory(llm=llm, input_key='question', output_key='answer', return_messages=True)
Search
Step 5: Setup Google Search
We use Google Search API for programmatically retrieving information.
import os
from langchain.chat_models.openai import ChatOpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.memory import ConversationSummaryBufferMemory
from langchain.utilities import GoogleSearchAPIWrapper
# Load Environment Variables
os.environ["OPENAI_API_KEY"] = "[INSERT YOUR OPENAI API KEY HERE]"
os.environ["GOOGLE_CSE_ID"] = "[INSERT YOUR GOOGLE CSE ID HERE]"
os.environ["GOOGLE_API_KEY"] = "[INSERT YOUR GOOGLE API KEY HERE]"
# LLM
llm = ChatOpenAI(model_name=”gpt-3.5-turbo-16k”, temperature=0, streaming=True,openai_api_key=”your_api_key”)
# Vectorstore
vectorstore = Chroma(embedding_function=OpenAIEmbeddings(), persist_directory=”./chroma_db_oai”)
# Memory for Retriever
memory = ConversationSummaryBufferMemory(llm=llm, input_key='question', output_key='answer', return_messages=True)
Search
# Search
search = GoogleSearchAPIWrapper()
Step 6: Initialize
We integrate WebResearchRetriever from LangChain as a knowledge source for LLM.
import os
from langchain.chat_models.openai import ChatOpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.memory import ConversationSummaryBufferMemory
from langchain.utilities import GoogleSearchAPIWrapper
from langchain.retrievers.web_research import WebResearchRetriever
# Load Environment Variables
os.environ["OPENAI_API_KEY"] = "[INSERT YOUR OPENAI API KEY HERE]"
os.environ["GOOGLE_CSE_ID"] = "[INSERT YOUR GOOGLE CSE ID HERE]"
os.environ["GOOGLE_API_KEY"] = "[INSERT YOUR GOOGLE API KEY HERE]"
# LLM
llm = ChatOpenAI(model_name=”gpt-3.5-turbo-16k”, temperature=0, streaming=True,openai_api_key=”your_api_key”)
# Vectorstore
vectorstore = Chroma(embedding_function=OpenAIEmbeddings(), persist_directory=”./chroma_db_oai”)
# Memory for Retriever
memory = ConversationSummaryBufferMemory(llm=llm, input_key='question', output_key='answer', return_messages=True)
Search
# Search
search = GoogleSearchAPIWrapper()
# Retriever
web_research_retriever = WebResearchRetriever.from_llm(
vectorstore=vectorstore,
llm=llm,
search=search,
)
Step 7: Run with Citations
RetrievalQAWithSourcesChain retrieves documents and provides citations.
import os
from langchain.chat_models.openai import ChatOpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.memory import ConversationSummaryBufferMemory
from langchain.utilities import GoogleSearchAPIWrapper
from langchain.retrievers.web_research import WebResearchRetriever
from langchain.chains import RetrievalQAWithSourcesChain
# Load environment variables for API keys
os.environ["OPENAI_API_KEY"] = "[INSERT YOUR OPENAI API KEY HERE]"
os.environ["GOOGLE_CSE_ID"] = "[INSERT YOUR GOOGLE CSE ID HERE]"
os.environ["GOOGLE_API_KEY"] = "[INSERT YOUR GOOGLE API KEY HERE]"
# Initialize the LLM
llm = ChatOpenAI(model_name=”gpt-3.5-turbo-16k”, temperature=0, streaming=True,openai_api_key=”your_api_key”)
# Setup a Vector Store for embeddings using Chroma DB
vectorstore = Chroma(embedding_function=OpenAIEmbeddings(), persist_directory=”./chroma_db_oai”)
# Initialize memory for the retriever
memory = ConversationSummaryBufferMemory(llm=llm, input_key='question', output_key='answer', return_messages=True)
Search
# Initialize Google Search API for Web Search
search = GoogleSearchAPIWrapper()
# Setup a Retriever
web_research_retriever = WebResearchRetriever.from_llm(
vectorstore=vectorstore,
llm=llm,
search=search,
)
# Define the User Input
user_input = “How do Planes work?”
# Initialize question-answering chain with sources retrieval
qa_chain = RetrievalQAWithSourcesChain.from_chain_type(chat_model, retriever=web_research_retriever)
# Query the QA chain with the user input question
result = qa_chain({"question": user_input_question})
# Print out the results for the user query with both answer and source url that were used to generate the answer
print(result["answer"])
print(result["sources"])
Step 7: Wrapping Up
Let’s encapsulate all this in a Python Class with provisions for dynamic user input:
import os
from langchain.chat_models.openai import ChatOpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.memory import ConversationSummaryBufferMemory
from langchain.utilities import GoogleSearchAPIWrapper
from langchain.retrievers.web_research import WebResearchRetriever
from langchain.chains import RetrievalQAWithSourcesChain
class QuestionAnsweringSystem:
def __init__(self):
# Set up environment variables for API keys
os.environ["OPENAI_API_KEY"] = "[INSERT YOUR OPENAI API KEY HERE]"
os.environ["GOOGLE_CSE_ID"] = "[INSERT YOUR GOOGLE CSE ID HERE]"
os.environ["GOOGLE_API_KEY"] = "[INSERT YOUR GOOGLE API KEY HERE]"
# Initialize components
self.chat_model = ChatOpenAI(model_name="gpt-3.5-turbo-16k", temperature=0, streaming=True, openai_api_key="your_api_key")
self.vector_store = Chroma(embedding_function=OpenAIEmbeddings(), persist_directory="./chroma_db_oai")
self.conversation_memory = ConversationSummaryBufferMemory(llm=self.chat_model, input_key='question', output_key='answer', return_messages=True)
self.google_search = GoogleSearchAPIWrapper()
self.web_research_retriever = WebResearchRetriever.from_llm(vectorstore=self.vector_store, llm=self.chat_model, search=self.google_search)
self.qa_chain = RetrievalQAWithSourcesChain.from_chain_type(self.chat_model, retriever=self.web_research_retriever)
def answer_question(self, user_input_question):
# Query the QA chain with the user input question
result = self.qa_chain({"question": user_input_question})
# Return the answer and sources
return result["answer"], result["sources"]
# Example usage:
qa_system = QuestionAnsweringSystem()
user_input_question = input("Ask a question: ")
answer, sources = qa_system.answer_question(user_input_question)
print("Answer:", answer)
print("Sources:", sources)
Unlock the Power of Cutting-Edge Technology with Top LatAm Talent
As we dive into the potential of LangChain and Google Search, it’s worth noting that the right team can make all the difference in leveraging these advanced technologies. Our pre-vetted LatAm developers are not only up-to-date with the latest trends and tools but also bring a wealth of experience to the table.
Whether you’re implementing LangChain to enhance search capabilities or exploring other innovative tech, our nearshore LatAm talent is equipped to deliver. By hiring through our nearshore staffing services, you gain access to developers who excel in using the latest frameworks and technologies. Our rigorous vetting process ensures you get professionals who are not just skilled but also aligned with your project needs.
Skip the 3-month hiring cycle. Start a 14-day risk-free trial with a pre-vetted LangChain and AI developers today.
Summary
It’s really cool to see how LLMs have created a whole lot of new opportunities and technologies for us to explore. This framework has caught my eye, and now I can’t stop exploring it. There’s a lot of other features, like connecting to a vector store, that we’ll dive into in subsequent posts.
Meanwhile, if you’re looking for top-tier tech talent, our pre-vetted LatAm developers are well-versed in the latest technologies and stay up-to-date with industry trends. Our nearshore staffing services ensure you find developers who fit your needs and excel in leveraging cutting-edge tech. Contact us today to build your team.