In the fast-paced world of natural language processing, OpenAI’s GPT-3.5-Turbo has emerged as a game-changing innovation. This advanced language model allows developers to fine-tune the language generation capabilities of the GPT (Generative Pre-trained Transformer) model. Developers can train the model on specific tasks and generate text that is tailored to their specific needs with remarkable precision, such as language translation, text summarization, and question answering. Tests have shown a fine-tuned version of GPT-3.5 Turbo can match, or even outperform, base GPT-4-level capabilities on certain narrow tasks.
Hire the best developers in Latin America. Get a free quote today!
Contact Us Today!In this comprehensive blog post, we’ll delve into the intricacies of GPT-3.5 Turbo Instruct, explore its practical applications, and how it can be used to improve the productivity of developers.
GPT-3.5 Turbo Explained
GPT-3.5 Turbo is a GPT-style language model that has been fine-tuned by OpenAI to be more adept at comprehending and adhering to instructions with the aid of human feedback. A fine-tuned model is a base model that has been trained (fine-tuned) for a specific task by providing it some examples of inputs and expected outputs. GPT-3.5 Turbo was developed by OpenAI as an extension of their popular GPT-3 model. GPT-3.5-Turbo-Instruct comes in three model sizes: 1.3B, 6B, and 175B parameters, with each subsequent model exhibiting greater complexity and sophistication.
Indeed, GPT-3.5-Turbo Instruct boasts significant improvements over GPT-4 in terms of truthfulness, reduced toxicity, and better alignment with user intent. The main idea behind GPT-3.5-Turbo Instruct is to enable developers to create unique and differentiated experiences for their users by training the model to follow very strict guidelines that are best explained by examples. Using GPT 3.5 Turbo Instruct, developers can now run supervised fine-tuning to make this model perform better for their use cases.
In our fine-tuning tests, we were able to meaningfully improve model performance across common use cases, allowing the model to perform a wide range of tasks such as data entry, data cleaning, and summarization, among others. This was achieved by fine-tuning the GPT-3.5 Turbo model on a large dataset of instructions and tasks, allowing it to learn to understand the meaning of instructions and how to complete the tasks.
How does GPT-3.5-Turbo Instruct Work?
The original GPT model is a language model that can generate human-like text by predicting the next word in a sentence based on the context provided by the previous words.
GPT-3.5-Turbo Instruct, on the other hand, is specifically designed to perform a certain task or set of tasks, such as answering questions, translating text, or summarizing articles, by fine-tuning the pre-trained GPT model on a specific task-specific dataset. This fine-tuning process is known as few-shot learning, where the model learns to adapt to the new task by leveraging the knowledge it has already acquired during pre-training.
Few-shot learning is a machine learning technique that enables a model to learn and make predictions based on very limited amounts of data. Few-shot learning can be applied to tasks such as few-shot text classification, question answering, and text generation, where the model is trained on a small number of examples per class. By leveraging its pre-training on a large corpus of text data, GPT-3.5-Turbo Instruct is able to generalize its knowledge to new classes with very few examples, making it a good candidate for few-shot learning. To apply few-shot learning in GPT-3.5-Turbo Instruct, fine-tuning on a small annotated dataset can be performed to adapt the model’s parameters to the specific task at hand. The resulting model can then be used to make predictions on new, unseen classes based on just a few examples.
At a high level, few-shot learning involves the following steps:
- Prepare and upload training data
- Train a new fine-tuned model
- Evaluate results and go back to step 1 if needed
- Use your fine-tuned model
GPT-3.5-Turbo Instruct Architecture
The architecture of GPT-3.5-Turbo Instruct is based on the transformer architecture, which is a type of neural network architecture that was first introduced in a 2017 paper by Google researchers. The transformer architecture is composed of multiple layers, each of which includes a self-attention mechanism and a feed-forward neural network. The self-attention mechanism allows the model to weigh the importance of different parts of the input when making predictions, while the feed-forward neural network is used to make the final predictions.
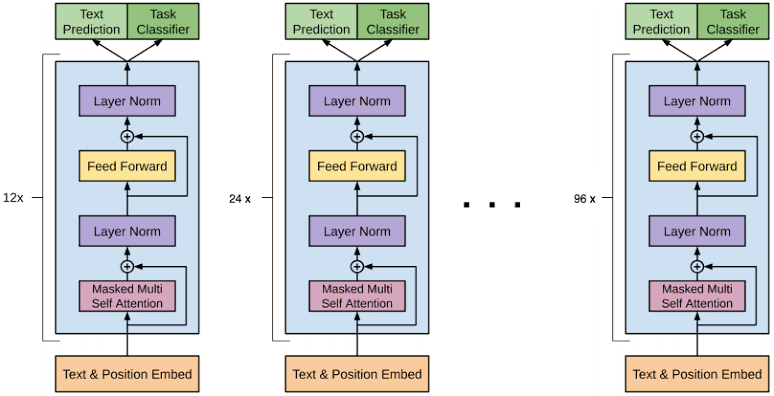
In the case of GPT-3.5-Turbo Instruct, the architecture is fine-tuned to perform specific tasks, such as language translation or question answering, by training it on a large dataset of examples for that task. The model is also pre-trained on a massive amount of text data to learn general language patterns, which helps improve its performance on various NLP tasks. Additionally, GPT-3.5-Turbo Instruct uses a technique called “few-shot learning” which allows the model to learn a new task with just a few examples, rather than requiring a large dataset of labeled examples.
How Can Developers Make the Most of GPT-3.5 Turbo Instruct?
Ever since OpenAI launched GPT-3.5 Turbo Instruct, professional software developers have found it surprisingly useful for a variety of use cases from analyzing and debugging code to generating code based on problem statements among other use cases.
Using OpenAI’s GPT-3.5 Turbo Instruct API, developers can swiftly build powerful applications in minutes or hours that previously would have taken days or weeks.
Here are some of the ways software developers can use GPT-3.5 Turbo Instruct to boost productivity:
1. Code Generation
GPT-3.5-Turbo Instruct can be fine-tuned to generate code snippets based on specific requirements, expediting the coding process and aiding in prototyping.
Developers can guide GPT-3.5 Turbo Instruct’s behavior, allowing it to adhere to coding standards, follow specific coding styles, or prioritize certain aspects of code optimization. This level of control results in more accurate and contextually relevant outputs, making it an indispensable tool in any developer’s arsenal.
2. Reliable Output Formatting
Fine-tuning GPT-3.5-Turbo improves the model’s ability to consistently format responses—a crucial aspect for applications demanding a specific response format, such as code completion or composing API calls. A developer can use fine-tuning to more reliably convert user prompts into high-quality JSON snippets that can be used with their own systems.
3. Data Analysis
GPT-3.5-Turbo-Instruct ability to comprehend instructions for specific analyses allows it to contribute to data-driven decision-making. By instructing GPT-3.5 Turbo Instruct on analytical tasks, developers can obtain insights into trends, patterns, or anomalies within the data, unlocking actionable insights and ultimately paving the way for better customer experiences. For example; convert “Who are my top customers?” to get_customers(min_revenue: int, created_before: string, limit: int) and calling your internal API.
4. Data Deduplication
Redundant data can skew analyses and impact the accuracy of insights. By training GPT-3.5 Turbo Instruct to identify and remove duplicate records, developers can ensure data integrity. This is crucial in maintaining a clean and reliable dataset, especially when dealing with large volumes of information.
5. Automating Testing Scenarios
Defining testing scenarios in natural language, allows for the automated generation of test cases and improves overall testing efficiency.
Software developers can articulate the specific conditions, inputs, expected outcomes, and actions that constitute a particular testing scenario.
Once the testing scenarios are defined in natural language, GPT-3.5 Turbo Instruct can be employed to automatically generate corresponding test cases. The model uses its pre-trained knowledge and fine-tuning capabilities to convert the descriptive instructions into actionable and executable test scripts. This automation eliminates the need for manual creation of individual test cases, saving time and effort.
GPT-3.5 Turbo Instruct’s versatility also allows it to handle a wide range of testing scenarios, from basic functionalities to complex user interactions. Whether it’s validating user inputs, testing system responses to specific conditions, or assessing error handling, the model can understand and generate test cases for diverse scenarios described in natural language.
How to Use GPT-3.5 Turbo Instruct?
GPT-3.5-Turbo Instruct is not intended for public use in the same way as ChatGPT, where anyone can access it via a web interface. Instead, it is aimed at developers and researchers who wish to leverage the capabilities of the model through their applications, products, or research projects. GPT-3.5-Turbo Instruct is accessible primarily through the API, which involves writing code and making API calls.
It is worth noting that the model is designed to be user-friendly and can be utilized by those without prior AI development experience to create and explore language modeling systems across various functions.
Fine-tuning GPT-3.5-Turbo Using Function Calling
Now that we have explored the basics of the fine-tuning API, let’s look at going through the fine-tuning lifecycle for function calling. The chat completions API supports function calling—including a long list of functions in the completions API.
Sometimes the model hallucinates or does not provide valid JSON output and therefore fine-tuning a model with function calling examples can allow you to:
- Get similarly formatted responses even when the full function definition isn’t present
- Get more accurate and consistent outputs
Below, we provide a step-by-step guide to effectively leverage the power of GPT-3.5 Turbo Instruct for your language modeling needs:
Step 1: Access the OpenAI API
To get started, you need to access the OpenAI API. If you haven’t done so already, you can sign up for an API key and obtain the necessary credentials.
Step 2: Prepare your Dataset
The second step in a fine-tuning job is to prepare data for training the model. You should create a diverse set of demonstration conversations that are similar to the conversations you will ask the model to respond to at inference time in production. Each exam dataset needs to be a conversation in the same format as OpenAI’s Chat Completions API.
In this example, our goal is to create a chatbot that gives weather updates for major cities, there is one training example (conversation) for our dataset but to follow along and create a fine-tuned model yourself, you will need to provide at least 10 examples:
{
"messages": [
{"role": "user", "content": "What is the weather in San Francisco?"},
{"role": "assistant", "function_call": {"name": "get_current_weather", "arguments": "{\"location\": \"San Francisco, USA\", \"format\": \"celsius\"}"}}
],
"functions": [{
"name": "get_current_weather",
"description": "Get the current weather",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string", "description": "The city and country, eg. San Francisco, USA"},
"format": {"type": "string", "enum": ["celsius", "fahrenheit"]}
},
"required": ["location", "format"]
}
}]
}
It’s typically recommended that you start with 50 to 100 training examples to see clear improvements although the right number can vary greatly based on the exact use case.
Step 3: Upload your training file
Once you have created your dataset, the file needs to be uploaded using the Files API in order to be used with a fine-tuning jobs:
from openai import OpenAI
client = OpenAI()
client.files.create(
file=open("mydata.jsonl", "rb"),
purpose="fine-tune"
)
Step 4: Create a fine-tuned model
After uploading the file, the next step is to create a fine-tuning job. To start a fine-tuning job using the OpenAI SDK:
from openai import OpenAI
client = OpenAI()
client.fine_tuning.jobs.create(
training_file="file-abc123",
model="gpt-3.5-turbo"
)
In this example, model is the name of the model you want to fine-tune (in this case, gpt-3.5-turbo) and training_file is the file ID that was returned when the training file was uploaded to the OpenAI API.
To retrieve the status of a job, run the following code:
from openai import OpenAI
client = OpenAI()
# Retrieve the state of a fine-tune
client.fine_tuning.jobs.retrieve("ftjob-abc123")
When a job has succeeded, you will see the fine_tuned_model field populated with the name of the model when you retrieve the job details and the model should be available right away for inference use. You can start making requests by passing the model name as shown below:
from openai import OpenAI
client = OpenAI()
completion = client.chat.completions.create(
model="ft:gpt-3.5-turbo:my-org:custom_suffix:id",
messages=[
{"role": "user", "content": "What is the weather like in San Francisco?"}
]
)
print(completion.choices[0].message)
Step 5: Analyze and Refine Output
Review the output generated by your custom GPT-3.5 Turbo model. Analyze its responses to see if it aligns with your intentions and the given instructions. If needed, refine the instructions and make subsequent API calls for better results.
If the results from a fine-tuning job are not as good as you expected, consider:
- Adding training examples that directly show the model how to do these aspects correctly
- Ensure your training examples contain all of the information needed for the response
- Ensure your all of your training examples are in the same format, as expected for inference
Limitations of GPT-3.5 Turbo Instruct
While GPT-3.5 Turbo Instruct represents a significant advancement in language models, it is not without limitations. Some of these limitations include:
1. Repetition and Coherence: GPT-3.5 Turbo Instruct may sometimes repeat itself semantically or lose coherence over long passages, resulting in contradictions or non-sequitur sentences.
2. Lack of Real-World Grounding: Like other large language models, GPT-3.5 Turbo Instruct lacks grounding in other modalities of experience, such as video or real-world interactions, limiting its context about the world.
3. Predominantly English: GPT-3.5 Turbo Instruct is primarily trained on English language data, which means it may not perform optimally on inputs in other languages or specific English dialects.
4. Interpretability and Predictability: Understanding how GPT-3.5 Turbo Instruct will behave in all situations is challenging, given the nature of deep learning systems.
5. High Variance on Novel Inputs: GPT-3.5 Turbo Instruct may not always be well-calibrated in its predictions on novel inputs, resulting in higher variance in performance compared to humans.
6. Biases: As with all language models trained on internet corpora, GPT-3.5 Turbo Instruct may generate content that reflects existing biases present in its training data, potentially leading to harmful outputs.
Summary
GPT-3.5 Turbo Instruct represents a significant leap forward in the field of natural language processing. Its meticulous instruction parsing and contextually relevant text generation make it a formidable tool for precision-based tasks. Built on the robust Transformer architecture and fine-tuned for specific tasks, it has the potential to enhance efficiency and effectiveness across various domains.
As the landscape of natural language processing continues to evolve, GPT-3.5 Turbo Instruct stands as a powerful tool that opens doors to a myriad of practical applications and innovations.
Further Reading
How To Use OpenAI GPT Turbo Vision API With Python
ChatGPT Vision. What is it? What can it do for my business?
Hire Nearshore AI Developers