ChatGPT has certainly carved a niche for itself in the realm of AI, but its closed-source nature and inability to access external datasets can sometimes limit its use, especially when it comes to personal documents. But what if you could leverage the capabilities of Python, Google Docs, ChatGPT, and LangChain to create your own advanced “Google Docs ChatGPT chatbot”?
Hire the best developers in Latin America. Get a free quote today!
Contact Us Today!Imagine having a Google Docs ChatGPT chatbot that can interact directly with files stored in your Google Drive.
So, whether you’re a developer, a tech enthusiast, or someone who just wants to streamline their work on Google Docs, stick around. This guide on creating your own “Google Docs ChatGPT chatbot” might just be the solution you’ve been seeking!
This article will cover:
- What is LangChain?
- Openai / ChatGPT Limitation
- Why Use a Google Docs ChatGPT Chatbot?
- LangChain Document Loaders
- Setting up Google API Credentials
- Step by step: How to build Google Docs ChatGPT Chatbot
What is LangChain?
LangChain is an innovative framework that is designed around the use of Large Language Models (LLMs). It was created by Harrison Chase and first introduced in late 2022. This powerful tool has grown popular due to the rise of generative AI and advancements in LLMs, like Google’s LaMDA chatbot, BLOOM, and OpenAI’s GPT-3.5 models.
What makes LangChain unique is its ability to ‘chain’ together various components, thus enabling advanced applications of LLMs. These applications range from chatbots and generative question-answering (GQA) to summarization tasks and more.
LangChain incorporates multiple key components in its structure. It uses ‘Prompt templates‘ which are predefined templates that can be adjusted to suit various types of prompts. These include prompts for chatbot-like interactions, question-answering in the style of ‘Explain it Like I’m Five’, and more.
Another critical part of LangChain is the LLMs themselves, including models like GPT-3 and BLOOM. These large language models form the core of LangChain’s functionality.
Then we have ‘Agents’, which use LLMs to determine the appropriate actions to take. They leverage tools like web search or calculators and wrap them into a logical operation loop.
Openai / ChatGPT Limitation
OpenAI’s API and ChatGPT have a key drawback: they struggle with large custom datasets. The max_token limit means you can’t put a lot of data into the context window. Plus, they’re not set up to handle individual document collections well. But LangChain helps to solve this. It uses Document Loaders to import and adapt data, so it works well with ChatGPT. This allows developers to make better use of their unique datasets with large language models.
Why Use a Google Docs ChatGPT Chatbot?
Why should you build a “Google Docs ChatGPT Chatbot”? The answer is simple – it provides you with the ability to converse directly with your Google Docs documents. By harnessing the capabilities of ChatGPT, langchain, and Python, this chatbot transforms your documents into an interactive platform. Imagine needing information about a company process or having questions about onboarding – with this chatbot, the answers are just a conversation away. It’s not just about accessing information, it’s about streamlining communication and making knowledge sharing more efficient.
LangChain Document Loaders
LangChain’s document loaders provide a robust solution for importing data from various sources and transforming it into Document objects. A Document object essentially contains a piece of text along with any associated metadata. The power of LangChain lies in its variety of document loaders. These include the CSV | 🦜️🔗 Langchain for working with CSV files, PDFLoader for handling PDF documents, a File Directory loader for importing data from a file system, and a JSON loader for processing JSON data.
loader = GoogleDriveLoader(
credentials_path=CLIENT_SECRET_FILE,
token_path=TOKEN_FILE,
folder_id=GOOGLE_DRIVER_FOLDER_ID,
recursive=False,
file_types=["sheet", "document", "pdf"],
)
return loader.load()What’s truly useful about these document loaders is their ‘load’ method. It extracts data from a configured source and turns it into Document objects. For more efficient memory utilization, LangChain also supports ‘lazy load’. This feature progressively loads data into memory as and when required, rather than loading it all at once. This functionality is not just limited to standard text files. For instance, LangChain can load the text contents of a web page or even fetch and process the transcript of a YouTube video, expanding the scope of data sources you can tap into.
Setting up Google API Credentials
In order to build our Google Docs ChatGPT chatbot, we will use GoogleDriveLoader document loader.
The GoogleDriveLoader is a document loader that allows you to ingest data from Google Docs into your LangChain project. It can load from a list of Google Docs document IDs or a folder ID.
To use the GoogleDriveLoader, you need to have a Google Cloud project and enable the Google Drive API. You also need to authorize credentials for a desktop app and install the necessary Python packages. Once you have set up the loader, you can use it to fetch data from Google Docs and integrate it into your LangChain project.
Setting up your Google Drive API credentials is an essential step when you’re looking to leverage Google Drive functionalities in your application. Let’s break it down step by step.
- Creating a new Google Cloud Project: Start by visiting your Google Cloud Console at https://console.cloud.google.com. If you’re not already signed into your Google account, you’ll be prompted to do so. Once in the Console, you can create a new project by clicking on the project dropdown (a triangle next to your Project Name) in the top left corner. A panel will slide open with a list of your projects and a ‘NEW PROJECT’ button at the top. Click on it, name your new project, and create it.
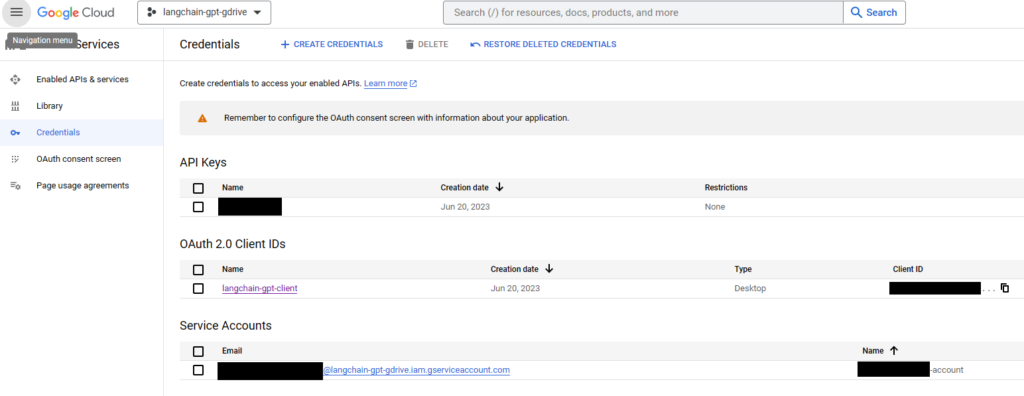
- Enabling the Google Drive API: After creating your project, you need to enable the Google Drive API for it. This can be done by visiting the ‘Library’ in the left sidebar. Here, search for ‘Google Drive API’, click on the resulting option, and then click ‘Enable’. If you don’t see the ‘Enable’ button immediately, you may need to refresh the page or navigate back to it once your new project is fully set up.
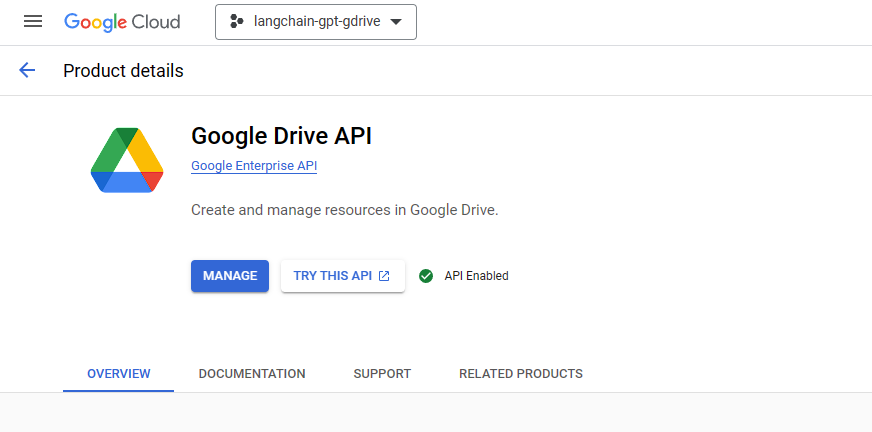
- Setting up Google API Credentials: This process involves four main steps:
- Authorize credentials for a desktop app: In the Google Cloud Console, navigate to ‘Credentials’ under ‘APIs & Services’. Click on ‘Create Credentials’ and select ‘OAuth client ID’. In the ‘Application type’, choose ‘Desktop app’. Enter a name for your OAuth client ID and click ‘Create’.
- Download your credentials: After creating, download the credentials by clicking on the download icon (a down arrow) next to the client ID you’ve just created. This will download a JSON file, such as
client_secret_23429870XXXXXXXXXXXXXX.json. - Configure your consent screen: Go to ‘OAuth consent screen’ under ‘APIs & Services’ and fill out the necessary details. This includes the app name, user support email, developer contact information, and more. This is the information users will see when your app requests access to their data.
- Add yourself as a test user: On the same ‘OAuth consent screen’, scroll down to the ‘Test users’ section and click on ‘Add Users’. Enter your email and save. This is especially important when your app is in a testing phase.
- Storing your Credentials: The credentials you downloaded come in a JSON file, which by default, LangChain expects to be stored at
~/.credentials/credentials.json. However for the sake of this project, we will place the credentials.json in the project root directory and point it using the GOOGLE_APPLICATION_CREDENTIALS variable.
Step by step: How to build Google Docs ChatGPT chatbot
Installing Python dependencies
pip install openai
pip install langchain
pip install chromadb
pip install PyPDF2
pip install sentence_transformers
pip install torch
pip install --upgrade google-api-python-client google-auth-httplib2 google-auth-oauthlibNote: when running the application, you may receive an error message AssertionError: Torch not compiled with CUDA enabled.
This is because the code relies on torch which needs to be installed as follows in order to support CUDA
pip uninstall torch
pip cache purge
pip install torch -f https://download.pytorch.org/whl/torch_stable.htmlCode Walkthrough
load_documents()
def load_documents():
loader = GoogleDriveLoader(
credentials_path=CLIENT_SECRET_FILE,
token_path=TOKEN_FILE,
folder_id=GOOGLE_DRIVER_FOLDER_ID,
recursive=False,
file_types=["sheet", "document", "pdf"],
)
return loader.load()
The load_documents() function is used to load documents from a specific Google Drive folder. The GoogleDriveLoader class from the langchain.document_loaders module is instantiated with several arguments: a path to the client secret file for authentication (CLIENT_SECRET_FILE), a path to the token file (TOKEN_FILE), and the ID of the Google Drive folder containing the documents (GOOGLE_DRIVER_FOLDER_ID). The recursive argument is set to False, which means the loader will not look for files in sub-folders of the specified folder. The file_types argument lists the types of files to load from the folder (in this case, Google Sheets, Google Docs, and PDF files). The function returns the loaded documents.
file_types: denotes the file types you want to index. “document” corresponds to “Google Docs” file type. GoogleDriveLoader will not index “.doc” or “.docx” files that you manually uploaded to the target folder.
Getting Google Drive Folder_ID
Getting the ID of a Google Drive folder is quite straightforward. Follow these steps:
- First, you’ll need to open your Google Drive in a web browser. This can be done by visiting the URL: https://drive.google.com.
- Navigate to the folder whose ID you want to retrieve.
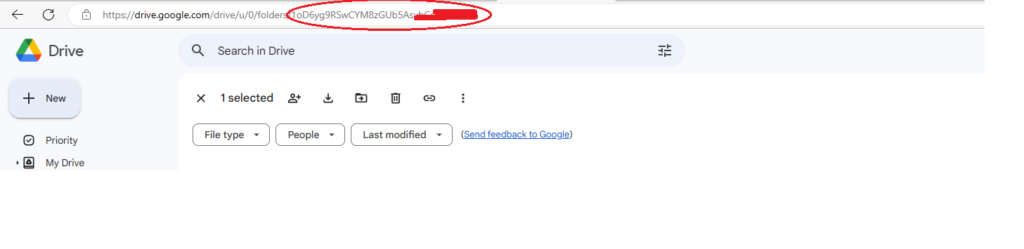
- Once you’re inside the folder, look at the URL in your web browser’s address bar. It should look something like this:
https://drive.google.com/drive/u/0/folders/1A2B3CDEFGH456I7J89K - The part of the URL after ‘folders/’ is the ID of the Google Drive folder. In the example above, the folder ID is
1A2B3CDEFGH456I7J89K. - Copy this ID and use it for “GOOGLE_DRIVER_FOLDER_ID” variable in your code.
split_documents(docs)
def split_documents(docs):
text_splitter = RecursiveCharacterTextSplitter(chunk_size=4000, chunk_overlap=0, separators=[" ", ",", "\n"])
return text_splitter.split_documents(docs)
The split_documents(docs) function is used to split the loaded documents into chunks. The RecursiveCharacterTextSplitter class from the langchain.text_splitter module is instantiated with specified arguments: chunk_size=4000 indicating that each chunk will contain approximately 4000 characters, chunk_overlap=0 indicating that there will be no overlapping characters between the chunks, and separators=[" ", ",", "\n"] indicating the preferred points (space, comma, or newline) at which to split the text. The function returns the document text split into chunks.
generate_embeddings()
def generate_embeddings():
return HuggingFaceEmbeddings(model_name=HUGGINGFACE_MODEL, model_kwargs=MODEL_KWARGS)
The generate_embeddings() function creates an instance of the HuggingFaceEmbeddings class from the langchain.embeddings module. The instance is created with the specified model name (HUGGINGFACE_MODEL) and additional keyword arguments (MODEL_KWARGS), which in this case is to specify that the model should run on a CUDA-enabled GPU. The function returns the HuggingFace embeddings generator.
create_chroma_db(texts, embeddings)
def create_chroma_db(texts, embeddings):
if not os.path.exists(PERSIST_DIRECTORY):
return Chroma.from_documents(texts, embeddings, persist_directory=PERSIST_DIRECTORY)
else:
return Chroma(embedding_function=embeddings, persist_directory=PERSIST_DIRECTORY)
The create_chroma_db(texts, embeddings) function creates a Chroma database that stores the embeddings for the chunks of text. The Chroma class is from the langchain.vectorstores module. If the specified persistence directory (PERSIST_DIRECTORY) does not exist, it creates a new Chroma database using the texts and their corresponding embeddings. If the directory already exists, it assumes the Chroma database has already been created, and just loads it using the Chroma() constructor, which needs the embeddings function and the persistence directory as arguments.
create_retriever(db)
def create_retriever(db):
return db.as_retriever(search_kwargs={"k": RETRIEVER_K_ARG})
The create_retriever(db) function creates a retriever object from the Chroma database. The retriever will be used to find the most relevant chunks of text based on a given query. The .as_retriever() method of the Chroma database object is used to create the retriever. The search_kwargs parameter is used to configure the search behavior of the retriever; here, it sets the “k” parameter, which determines the number of top results to retrieve.
create_index(llm, retriever)
def create_index(llm, retriever):
return RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=retriever)
The create_index(llm, retriever) function uses the RetrievalQA class from the langchain.chains module to create an index that combines a language model (llm) and a retriever. The from_chain_type() static method is used to create the index, with “default” as the chain type, and the provided language model and retriever as arguments.
create_llm()
def create_llm():
return ChatOpenAI(temperature=0, model_name=OPENA_AI_MODEL)
The create_llm() function is used to instantiate an instance of the ChatOpenAI class from the langchain.chat_models module, which represents a language model. The temperature parameter is set to 0, indicating that the model’s outputs will be deterministic (i.e., always choosing the most probable next word). The model_name is set to OPENA_AI_MODEL, a constant that refers to a specific version of the OpenAI model to use (in this case, “gpt-4-0314”). The function returns the instantiated language model.
main()
def main():
docs = load_documents()
texts = split_documents(docs)
embeddings = generate_embeddings()
db = create_chroma_db(texts, embeddings)
retriever = create_retriever(db)
llm = create_llm()
qa = create_index(llm, retriever)
while True:
query = input("> ")
if query.lower() == "exit":
exit()
answer = qa({"query": f"### Instructions. {PRE_PROMPT_INSTRUCTIONS} ###Prompt {query}"})
print(answer['result'])
if __name__ == "__main__":
main()
The main() function orchestrates the entire process of loading, processing, and querying documents.
- The function then enters an infinite loop, where it repeatedly asks the user for a query (with
input("> ")). The loop continues until the user enters “exit”, at which point the program exits. - If the input isn’t “exit”, the function treats the input as a query and passes it to the
qaobject (the index created earlier), which is responsible for producing a response. This response is then printed out.
First run
The first time you correctly execute your program, it will automatically open a web browser prompting you to sign in to your Google account. You should log in with the account that you previously set up as a test user during the preparation stage. Once you’ve successfully authenticated your account, the application will quietly generate a token.json file and download it.
Note: the token file name is whatever value you specify in TOKEN_FILE variable.
This file will contain the necessary tokens to access your Google account and it will be used for future sessions, eliminating the need for you to manually log in each time you run the program.
Conclusion
This kind of chatbot has a wide variety of use-cases, especially where dealing with large amounts of text data is involved. Here are a few examples:
- Research: If you’re a researcher dealing with a large corpus of articles, papers, or reports, this program can help you find relevant information quickly. Instead of manually reading through each document, you can query the system and get the information you need.
- Legal Work: In legal professions, there’s often a need to comb through large volumes of legal documents, cases, or laws to find relevant references or precedents. This system could drastically reduce the time spent on such tasks.
- Customer Support: This could be used in a company’s customer support to quickly find answers to customer queries based on a large database of product manuals, previous support tickets, and other documentation.
- Education: Teachers and students could use this to quickly find relevant study material from a large corpus of textbooks, articles, and other educational resources.
- Content Creation: Writers and content creators could use it to quickly find inspiration, references, or background information from a vast collection of documents.
- Business Intelligence: Companies could use this system to extract insights from a vast amount of business reports, meeting minutes, or emails.
- Healthcare: Medical practitioners can use it to search through a large collection of medical literature, case studies, research papers, and find treatment options, diagnose diseases, etc.
You can find the code in this github repository